PromptMule
- Web
- Mobile
- Desktop

PromptMule is a managed caching service that delivers lightning-fast responses while reducing costs. It intelligently stores and retrieves AI model outputs, allowing applications to rapidly respond to user queries without expensive re-computation by employing advanced techniques like semantic caching, vector embeddings, and intelligent query matching, thus empowering developers and businesses to create high-performance, cost-effective, secure and easily scalable AI-powered applications that users can trust
At its core, PromptMule uses semantic caching to identify and store similar queries and responses. It leverages AI embeddings, which are numerical representations of text, to enable fast similarity search of cached data. This approach, similar to Retrieval Augmented Generation (RAG), dramatically increases cache hit rates and performance.
To illustrate, imagine a user asks an AI assistant "What is the capital of France?" PromptMule would check its cache, and if a similar query like "What is the capital city of France?" had been asked before, it would return the cached response instantly. This avoids a costly round-trip to the AI model, significantly speeding up the interaction.
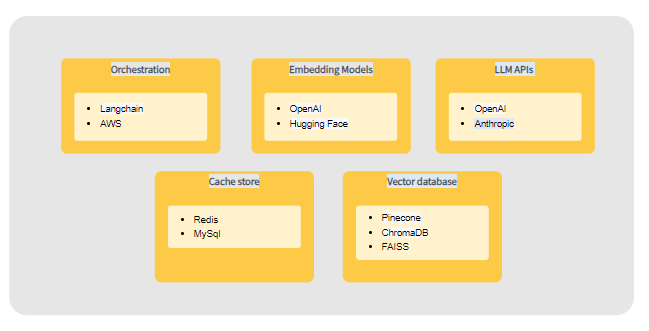
PromptMule's technology abstracts away complexity, allowing developers to leverage advanced caching without getting into the weeds. The key components include:
Under the hood, PromptMule leverages various AWS services to ensure scalable, secure, and reliable operation. API Gateway handles API requests, RDS provides fast and reliable storage, and purpose-built vector databases manage embeddings. The serverless architecture automatically scales to handle any load.
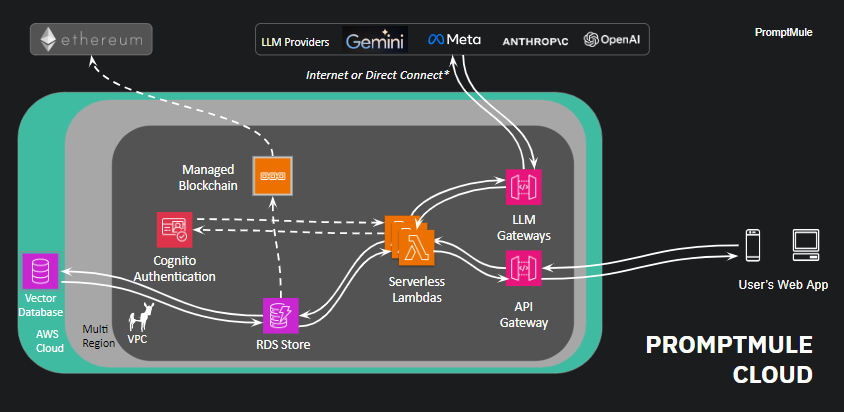
PromptMule's architecture is powered by several key AWS services that work together seamlessly:
The API Gateway serves as the central entry point, efficiently handling and processing a high volume of concurrent API requests. It manages traffic, ensures secure access control, and provides comprehensive monitoring.
To accelerate data retrieval, PromptMule utilizes Amazon ElastiCache, a high-speed in-memory data store. ElastiCache is fine-tuned with customized cache expiration settings, data store limits, and dynamic auto-scaling to optimize cache performance under varying loads.
At the core of PromptMule's intelligent caching mechanism are the Vector Databases, which are specialized for managing vector embeddings. These databases efficiently handle the unique numerical representations generated from textual prompts by AI models like Large Language Models. By comparing the similarity of these embeddings, PromptMule swiftly retrieves relevant data from the cache, dramatically improving response times.
Through the synergy of these powerful AWS components, PromptMule delivers a highly performant, scalable, and secure caching solution that greatly enhances the speed and efficiency of AI applications.
PromptMule represents a leap forward in making high-performance AI accessible and cost-effective for all developers. By democratizing access to state-of-the-art caching technology, it enables a new generation of engaging, real-time AI experiences. PromptMule eliminates the complexity and expense traditionally associated with optimizing AI applications, empowering teams to ship better products faster.
PromptMule was founded by two longtime friends with a shared passion for technology and a combined experience of over 20 years in product management and engineering. Having worked together at one of the world's largest security companies, they recognized the immense potential of generative AI and set out to create a solution that would revolutionize the way AI applications create trust, transparency, and traceability.
"PromptMule transformed our customer support. Our users now enjoy instant, reliable help, and our support team can focus on what really matters. It's been a game-changer for our customer satisfaction and operational efficiency." - Isaac Wu, Head of Customer Support, QuantumDot